Learning Objectives
The learning objectives for Extreme Edge Cases are:
- Test Driven Development
- Thinking of Edge Cases
- String Manipulation
- C Programming
Backstory #
What makes code good? Is it camelCased strings? Good comments? Descriptive variable names, perhaps?
One thing we know is that good code is generally modular - it consists of discrete “units” of functionality that are only responsible for very specific and certain behavior. In our case, working with C, these “units” are functions.
For example, the C string function strlen is solely responsible for determining the length of a string; it doesn’t do any I/O or networking, or anything else. A function that knows all and tries to do all would be bad design, and testing whether that kind of function adheres to expectations would be nontrivial.
A programmer might ask, “do my units of work behave the way I expect?” or “if my function expects a string, how does it behave when given NULL?”. These are crucial questions, since ensuring that units of code work exactly the way one would expect makes it easy to build reliable and robust software. An unreliable unit in a large system can affect the entire system significantly. Imagine if strcpy, for example, did not behave properly on all inputs; all of the higher-level units that use strcpy, and all of the units that interact with those units, would in-turn have unpredictable behavior, and so the unreliability would propagate through the whole system.
Enter unit testing.
Unit Testing #
Unit testing is a ubiquitous and crucial software development method used heavily in industry. According to artofunittesting.com, “a unit test is an automated piece of code that invokes a unit of work in the system and then checks a single assumption about the behavior of that unit of work”. This sounds like testing - leave it to the QAs, right? Actually, developers, much to their chagrin, are expected to write their own unit tests.
In order to write effective unit tests, all possible cases of input to a unit (mainly functions, in C), including edge cases, should be tested. Good unit tests test (extreme) edge cases, making sure that the discrete unit of functionality performs as specified with unexpected inputs.
In this MP, your goal is to create and test the behavior of an arbitrary string manipulation function to determine if it is reliable, predictable, and correct. While writing your functions, try to write modular code, as this will make your life easier when you test it. You’ll learn how to write effective test cases - an incredibly helpful skill for the rest of the course. Finally, you’ll be able to take these skills to Facenovel for your next internship and impress your coworkers.
Man pages #
The man (manual) pages are the main system of documentation for C system calls, library functions, and other information related to Unix-based operating systems like Linux.
Learning how to use documentation to unblock yourself when stuck is an integral part of software development, in CS 341 and beyond. For the purposes of this course, the man pages are an excellent resource to direct documentation-related questions to. For example, some good questions related to this MP to direct to the man pages:
- What does
strtoktake as input, and what does it return? - What is the difference between
strcpyandstrncpy? - Which characters are considered whitespace characters by
isspace?
You can view the man pages through your terminal’s command-line interface by typing in man <command> or man <function>, like man ls or man malloc. The man pages are also accessible via several sites on the web, such as
- https://man7.org/linux/man-pages/
- https://linux.die.net/man/
camelCaser #
We have chosen
char **camel_caser(const char* input)
as your arbitrary string manipulation function.
Your manager at Facenovel, to celebrate Hump Day, has asked all of the interns to implement a brand new camelCaser to convert sentences into camelCase. To give you a chance to earn your return offer, he also assigned you to write test cases for all the other interns’ implementations of camelCaser, with the implementations hidden from you.
Let’s say I want to get a sequence of sentences in camelCase. This is the string passed into your method:
"The Heisenbug is an incredible creature. Facenovel servers get their power from its indeterminism. Code smell can be ignored with INCREDIBLE use of air freshener. God objects are the new religion."
Your method should return the following:
["theHeisenbugIsAnIncredibleCreature",
"facenovelServersGetTheirPowerFromItsIndeterminism",
"codeSmellCanBeIgnoredWithIncredibleUseOfAirFreshener",
"godObjectsAreTheNewReligion",
NULL]
The brackets denote that the above is an array of those strings.
Here is a formal description of how your camelCaser should behave:
- You can’t camelCase a NULL pointer, so if
inputis a NULL pointer, return a NULL pointer. - If
inputis NOT NULL, then it is a NUL-terminated array of characters (a standard C string). - A input sentence,
input_s, is defined as any MAXIMAL substring of the input string that ends with a punctuation mark. This means that all strings in the camelCased output should not contain punctuation marks.- This means that “Hello.World.” gets split into 2 sentences “Hello” and “World” and NOT “Hello.World”.
- Let the camelCasing of
input_sbe calledoutput_s. -
output_sis the the concatenation of all wordswininput_safterwhas been camelCased.- The punctuation from
input_sis not added tooutput_s.
- The punctuation from
- Words are nonempty substrings delimited by the MAXIMAL amount of whitespace.
- This means that
" hello world "is split into"hello"and"world"and NOT"hello "," "," world"or any other combination of whitespaces.
- This means that
- A word
wis camelCased if and only if:- it is the first word and every letter is lowercased.
- it is any word after the first word, its first letter is uppercased and every subsequent letter in the word is lowercased.
- Punctuation marks, whitespace, and letters are identified by
ispunct,isspace, andisalpharespectively.- These are functions in the C standard library, so you can
man ispunctfor more information. - If
input_shas ANY non-{punctuation, letter, whitespace} characters, they go straight intooutput_swithout any modifications. ALL ASCII characters are valid input. Your camelCaser does not need to handle all of Unicode.
- These are functions in the C standard library, so you can
-
camel_caserreturns an array ofoutput_sfor everyinput_sin the input string, terminated by a NULL pointer.
Hint: ctype.h has a lot of useful functions for this.
Your implementation goes in camelCaser.c, and you may not leak any memory.
Destroy
You must also implement destroy(char **result), a function that takes in the output of your camel_caser() and frees up any memory used by it. We will be calling this in our test cases and checking for memory leaks in your implementation, so remember to test this!
camelCaser Result In Memory
camel_caser() takes in a C string, which represents an arbitrary number of sentences, and returns a pointer to a NULL-terminated array of C strings where each sentence has been camelCased. It is up to you how the resulting structure is allocated, but it must be completely deallocated by your destroy() function.
For those who like pictures, here is what the return value of camelCaser looks like in memory:
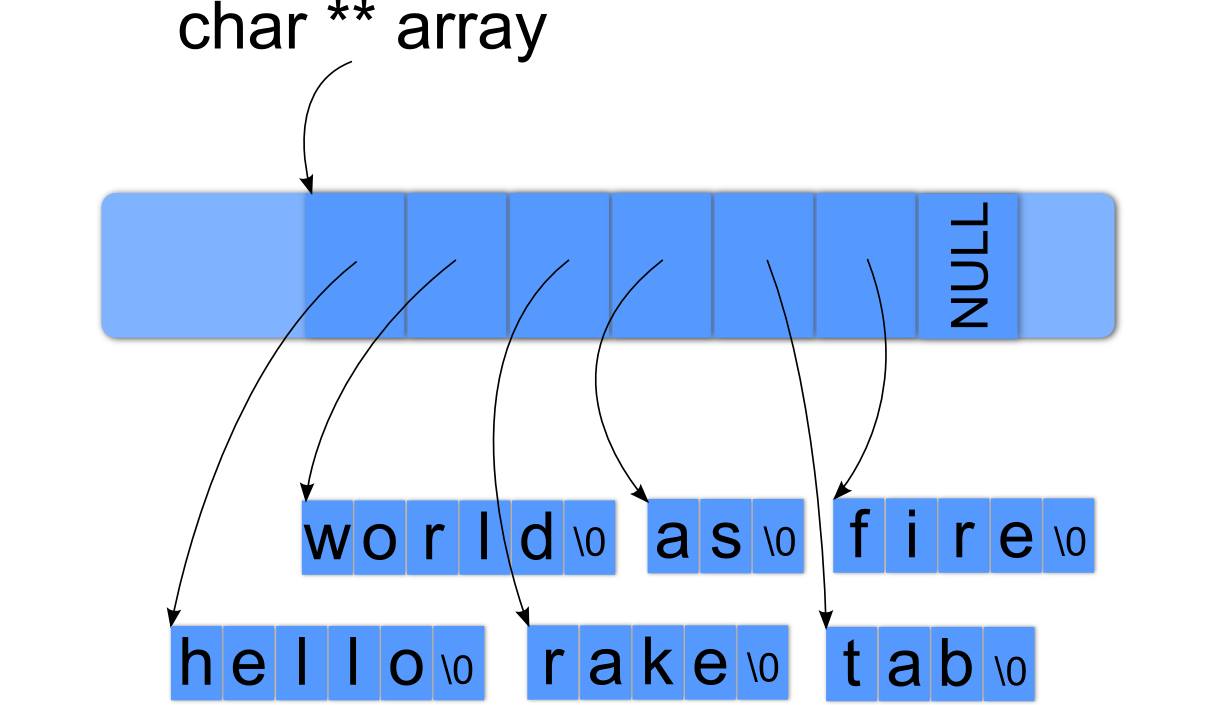
In the above picture, you can see that we have a char double pointer called ‘array’. In this scenario, the char double pointer points to the beginning of a NULL-terminated array of character pointers. Each of the character pointers in the array points to the beginning of a NUL-terminated char array that can be anywhere in memory.
These arrays are NULL-terminated because your user will need to know when these arrays end so they do not start reading garbage values. This means that array[0] will return a character pointer. Dereferencing that character pointer gets you an actual character. For demonstration purposes, here is how to grab the character “s” in “as”:
// Take array and move it over by 3 times the size of a char pointer.
char **ptr = array + 3;
// Deference ptr to get back a character pointer pointing to the beginning of "as".
char *as = *ptr;
// Take that pointer and move it over by 1 times the size of a char.
char *ptr2 = as + 1;
// Now dereference that to get an actual char.
char s = *ptr2;
Writing Unit Tests #
Your goal is to show that the other interns’ implementations of camelCaser - which, of course, you can’t see directly - fail on some extreme test cases, and, in the meantime, demonstrate to the head honcho at Facenovel exactly how robust your own function is.
Facenovel promises to pass in C-strings. Likewise, you promise to return a dynamically allocated NULL-terminated array of C strings that can be deallocated with your destroy() function.
What kinds of edge cases might come up?
Run make camelCaser to test. You will have to fill in tests in camelCaser_tests.c.
Because Facenovel values their testing server time, you may not try more than 16 different inputs, and each input must be less than 256 characters (only characters). This does NOT mean your implementation can assume input of 256 characters or less. Your implementation of camel_caser() should be able to handle any valid C string of any length with any combination of ASCII characters.
Also, it is not in the spirit of unit testing to diff the output of your implementation with the one you are testing. Therefore, you may NOT call your own camel_caser() function when implementing your test cases.
Other helpful resources: Test-Driven Development
Reference Implementation #
Your senior coworkers at Facenovel have taken a liking to you for your work ethic, and they decided to help you by providing you a reference implementation. You are given an interface camelCaser_ref_tests.c which allows you to access the black-box reference implementation. You are given two utility functions to help you understand what camelCase looks like.
The first function provided isprint_camelCaser(char *input). It takes a string input and prints out the transformed camelCased output onto stdout. This function is meant to be used to help you answer questions like, “What should be the result of inputting <blah> into camel_caser()?” Note that this function might behave weirdly with non-printable ASCII characters.
The second function that you can use is check_output(char *input, char **output). This function takes the input string you provided and the expected output camelCased array of strings, and compares the expected output with the reference output. This function is to be used as a sanity check, to confirm your understanding of what the camelCased output is like. This will also help you to understand how to deal with non-printable ASCII characters.
A few important things to be aware of when you use the reference implementation:
-
DO NOT use any functions provided in
camelCaser_ref_tests.candcamelCaser_ref_utils.hin any part of yourcamel_caser()implementation as well as your unit tests (that is, don’t use it anywhere outside ofcamelCaser_ref_tests.c). Your code will definitely not compile during grading if you use any of those functions in any graded files. - The reference only serves as a starting guideline and a sanity check, to ensure that you understand how camelCase works. The reference implementation does not represent the only possible good implementation. Your implementation is restricted by the specifications provided above, and only the specifications above. An implementation is good if and only if it meets the requirements in the specifications.
- The reference does not replace actual testing of your own implementation. You are responsible to rigorously test your own code to make sure it is robust and guards against all possible edge cases. You may not use the reference implementation to test your implementation of
camel_caser().
To use the reference, modify the camelCaser_ref_tests.c file, run make camelCaser_ref and you should have a camelCaser_ref executable.
Note: The reference implementation is only available in release form. There is no debug version of the reference.
Grading #
Grading is split up into two parts.
Your Implementation
The first portion of the test cases test your implementation of camel_caser(). We pass in some input, and check that your output matches the expectations laid out in this document. Essentially, your code is put up against our unit tests, which means you can write as-good (or even better) unit tests to ensure that your camel_caser() passes ours.
Your Unit Tests
The second portion of the test cases test your unit tests. We have a handful of camel_caser() implementations, some that work, and some that don’t. To test your unit tests, we feed each of our camel_caser() implementations through your test_camelCaser() function (found in camelCaser_tests.c) and see if it correctly identifies its validity.
For each of the camel_caser() implementations that you correctly identify - marking a good one as good, or a bad one as bad - you get a point. To prevent guessing, randomization, or marking them all the same, any incorrect identification loses you a point. However, after each autograde run, we will tell you how many good ones you correctly identified and how many bad ones you identified, so you know which unit tests may need improvement.
If your unit test segfaults or otherwise crashes, our test will interpret that as evaluating that implementation as a bad one.
You cannot assume anything about the input, other than the input string being NUL-terminated, just like all C strings.
Example
Let’s say there are five good implementations and five bad implementations. If you correctly say all five good are good, then you’d get +5 points. If you correctly identify three of the bad ones as bad, then you would get +3 for those and -2 for incorrectly labeling the others. In this case, you’d get a 6/10.
Tips and tricks on approaching assignments #
- Always read the documentation entirely, before beginning to approach the assignment. Note down what you need to do, and what you should not be doing. Keep a checklist of things to implement to prevent yourself from forgetting things.
- Read the header files of the assignments first. These files will contain comments on the behavior of functions. Please report to staff if a function is not sufficiently documented.
- Work incrementally. Add in a function or two, then test to make sure it works before moving on.
- Test extensively. Be the most evil user you can be, and try various nasty (but valid) inputs to see if your code handles them or not.
- Good function/variable naming and well placed comments save lives.
- For every
mallocyou call, make sure there is a correspondingfreesomewhere. - Pay attention to the small details (such as function return values, side effects, etc). C is a language where every detail matters.
- Make sure your code works in the
releasebuild, as we will run tests on that build (see Luscious Locks documentation for a detailed explanation of the different builds). - Always debug your code using the
debugbuild, as the debug build is compiled with the-O0flag, which means no compiler optimizations. In addition, the debug build is compiled with the-gflag. This allows you to view source code in GDB, and shows the line numbers where things fail in Valgrind. - Ensure that the code you submitted is the version that you want to grade (before the deadline, or before running an autograder run).
- Take note of graded files. Make sure any changes you want graded are placed in the graded files.
- Do not declare your functions as just
inline, as it is a keyword that may cause issues with linkage. Functions declared withinlinewill not have an external definition (unless overrided with keywords likeextern), so it may be considered undefined unless an explicit external definition is provided. In addition, the auto-grader compiles the code in debug mode for valgrind checks, whichinlinecan break. You can read more about this here or here in the docs. - Pay attention to Ed for pitfalls and issues that you may have overlooked.
Print smart
Many assignments in this course will read your output and grade them. This means that having stray prints may cause you to randomly fail tests. Furthermore, excessive logging prints can reduce the performance of your code, which can also cause you to fail tests. Therefore, you should always check your code to make sure you don’t have random prints in your code. Instead of writing print statements and removing them repeatedly, a recommended strategy is to use the following function below to perform logging:
//You may want to consider using the #define directive for this, especially if you're using this in multiple files
void log(char *message) {
#ifdef DEBUG
fprintf(stderr, "%s\n", message);
#endif
}
The DEBUG macro is enabled in the debug build by passing the flag -DDEBUG to the compiler when compiling the debug build of an assignment (please report to staff if an assignment’s debug build does not have the -g or -DDEBUG flags). The #ifdef statement is a preprocessor directive which includes a code snippet into the executable if the macro is enabled during compilation. Therefore, statements in #ifdef DEBUG blocks do not appear in release builds of assignments. This will prevent you from impacting the performance of release builds (if you need these logging prints in release builds, remove the #ifdef directive). Furthermore, this logging function prints to stderr. We typically do not check what’s in stderr, so feel free to use that output stream to dump your logging messages.
Hint: hexdump!
hexdump is a command-line utility that displays the contents of files in convenient ways. For example, you can view the exact bytes of a file, formatted in hexadecimal (according to ASCII). If no file is specified, hexdump will read from stdin. Thus, by piping your program’s output into hexdump -C, you can see exactly what bytes are being written, including non-printable ASCII characters:
$ ./camelCaser | hexdump -C
errno knows what’s up
Often, you’ll see that system calls and library functions will return -1 and set errno upon execution failure. errno is a special global variable that stores the error codes for failures in function calls. Many system calls do not guarantee success and can fail at random, even malloc! Therefore, whenever you encounter bizarre failures, one thing to keep in mind is to check if a function/system call failed, and if so, determine why it failed. Attached below is a sample code snippet of reading errno using perror:
#include <errno.h> //You will need to include this if you want to access errno
ssize_t bytes = read(0, buf, 50);
if (bytes == -1) {
perror("read failed");
}
A note on strtok
Using strtok (instead of strchr) for this MP can be confusing without an understanding of how it works, and often leads to pitfalls. An important fact about strtok to keep in mind for this MP is that it ignores multiple consecutive separators when parsing a string. If you still choose to use strtok, read the first few paragraphs of the man page thoroughly.
$ man strtok
STRTOK(3) Linux Programmer's Manual STRTOK(3)
NAME
strtok - extract tokens from strings
SYNOPSIS
#include <string.h>
char *strtok(char *str, const char *delim);
DESCRIPTION
The strtok() function breaks a string into a sequence of zero or more nonempty tokens. On the first call to strtok(), the string to be parsed
should be specified in str. In each subsequent call that should parse the same string, str must be NULL.
The delim argument specifies a set of bytes that delimit the tokens in the parsed string. The caller may specify different strings in delim
in successive calls that parse the same string.
Each call to strtok() returns a pointer to a null-terminated string containing the next token. This string does not include the delimiting
byte. If no more tokens are found, strtok() returns NULL.
...
Good luck!