MapReduce
Inter Process Communication
The goal of IPC is to communicate between different processes. Common ways to do IPC include:
- Pipes
- Sockets
- Shared Memory
Pipes
- Takes in a stream of bytes from an input file descriptor
- Spits out the data through an output file descriptor
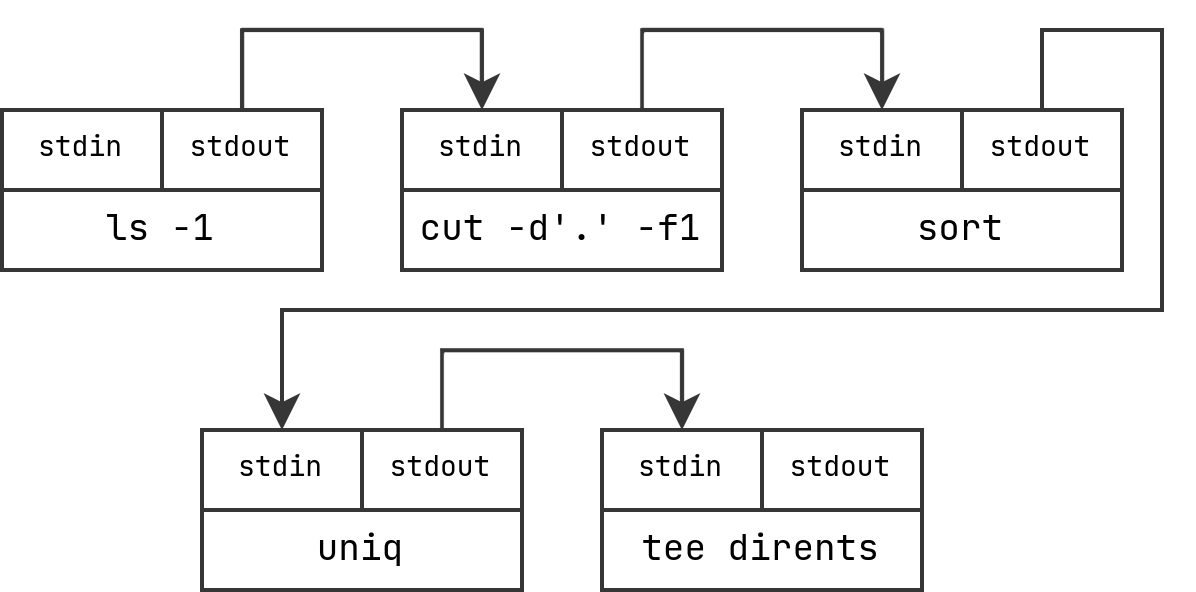
Pipes in the shell
> ls -1 | cut -d'.' -f1 | sort | uniq | tee dirents
Pipes in code
int pipe(int pipefd[2]);
-
pipe()takes a single argument - an array of size 2. - It sets
pipefd[0]to the reading end fd. - It sets
pipefd[1]to the writing end fd.
Pipe capacity
How much data can a pipe hold?
Pipes' capacity depends on system configuration, but usually it ranges from 4 KiB to 128 KiB.
Check /proc/sys/fs/pipe-max-size!
Reading from a pipe
- Returns 0 if all writing ends are closed.
- Blocks if pipe is empty and active writing ends exist.
- Unblocks when data is written so pipe becomes nonempty.
Writing to a pipe
- Generates a
SIGPIPEif all reading ends are closed. - Blocks if pipe is full and active reading ends exist.
- Unblocks when data is read so pipe becomes nonfull.
Note: SIGPIPE kills your program by default. Catch or ignore it to see write() returning -1 and setting errno to EPIPE.
pipe() vs pipe2()
pipe2() has an additional argument (flags).
O_CLOEXEC closes both pipe fds on a successful exec.
Mapreduce
What is MapReduce?
- A programming model: Map, then Reduce
- Originally developed at Google to process large datasets with distributed systems
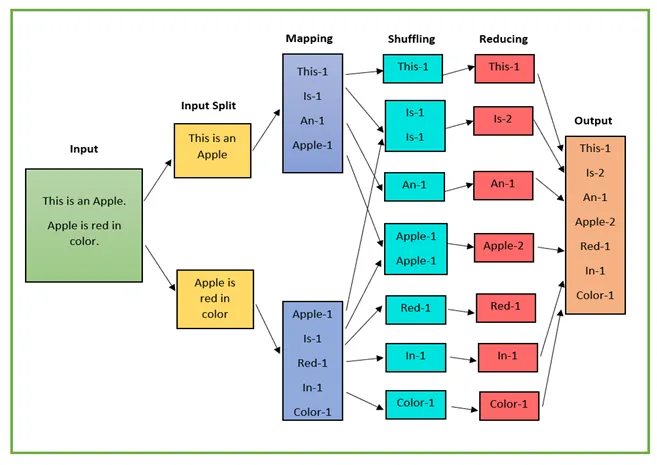
- Map: transform raw data into processed data
- Reduce: aggregate processed data into statistics
- The 341 MapReduce is vastly oversimplified
MapReduce Example
Parallelism
- Mapping is parallelizable: The mapper function is independent per input element
- Assign different chunks across mappers
- Reducing is parallelizable: The reducer function is associative -
reduce(A[1...n]) = reduce(reduce(A[1...n/2]) + reduce(A[n/2...n])) - Run multiple reducers together, then reduce the output from reducers
Lab Assignment
Implement the MapReduce orchestrator:
- Split up the inputs
- Send them off to mappers
- Agglomerate the mapped outputs into a final result via a reducer
No need to implement mappers or reducers yourself, and a splitter tool is already provided.
Implementation
./mapreduce <input_file> <output_file> <mapper_executable> <reducer_executable> <mapper_count>.
- Split the input file into
<mapper_count>chunks using the givensplittertool. - Start a mapper process for each chunk, and pipe the output of each mapper process into the input of the singular reducer process.
- Pipe the output of the reducer process to the output file.